초록
- 도입: 신경망 기반 기계 번역(neural machine translation, NMT)의 새로운 접근법 제안
- 기존 연구: 기존의 통계적 번역 모델(statistical machine translation, SMT)과 달리, 단일 신경망이 번역 성능을 극대화
- 방법: 고정된 길이의 벡터로 문장을 표현하는 기존 인코더-디코더 모델의 한계를 극복하고, 소프트 얼라인먼트(soft alignment) 방식을 도입하여 번역 성능을 개선
- 결과: 긴 문장에서도 우수한 성능을 보이며, 영어-프랑스어 번역에서 기존 시스템(최첨단 구문 기반 시스템)과 유사하거나 더 나은 결과를 얻음
1. 서론
- 신경망 기반 기계 번역(NMT): 전체 문장을 입력받아 출력 문장을 생성하는 단일 모델
- ↔ 통계적 번역 시스템(SMT): 작은 하위 요소로 구성된 기존의 구문 기반 번역 시스템의 복잡한 구성 요소를 통합
- 인코더-디코더 방식
- 대부분의 신경망 기계 번역 모델이 속함
- 각 언어마다 인코더 디코더 존재 or 각 문장에 언어별 인코더 적용한 후 다음 출력 비교
- 문제점: 입력 문장을 고정 길이 벡터로 압축, 긴 문장에서 성능 저하 발생
- 해결 방안: 소스 문장에서 가장 관련성 높은 정보가 집중된 위치 집합(soft) 검색 → 위치 & 단어 관련 문맥백터 기반으로 대상 단어 예측
2. 배경: NMT 및 RNN 인코더-디코더
- 확률론적 관점 번역 vs 신경망 기계 번역
- NMT는 확률적 관점에서 조건부 확률 p(y∣x)를 최대화하는 방향으로 학습
- 신경망 기계 번역
- 개념: x 문장 인코딩 → 목표 문장 y로 디코딩
- 신경망을 사용하여 이러한 조건부 분포를 직접 학습할 것을 제안( Kalchbrenner and Blunsom, 2013…)
- LSTM
- 장단기 메모리(LSTM) 유닛을 갖춘 RNN 기반의 신경 기계 번역이 영어-불어 번역 작업에서 기존 구문 기 반 기계 번역 시스템의 최첨단 성능에 근접하는 결과를 달성(Sutskever et al., 2014)
2-1. RNN 인코더-디코더
- 개념: 입력 문장을 고정된 벡터로 변환하고, 이를 통해 출력 문장을 생성(Cho et al., 2014a; Sutskever et al., 2014).
- 인코더: 입력 문장(벡터 시퀀스 x)을 읽고 벡터 c로 변환
- h = hidden state at time t, c = vector generated from hidden state
- 디코더: 문맥 벡터 c + 이전에 예측된 단어 yt-1을 고려하여 다음 단어 yt 예측
- = 공동 확률(joint probability)을 정렬된 조건부(ordered conditional)로 분해하여 번역 y에 대한 확률 정의
- g = y의 확률을 출력하는 비선형, 잠재적으로 다층적인 함수, s=RNN의 hidden state

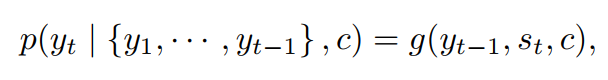
3. 학습 방식: 정렬과 번역의 결합 학습
3.1 디코더
- 컨텍스트 벡터 c
- #2와 차이점: 각 대상 언어 y에 대해 별개의 컨텍스트 벡터 c를 조건으로 확률을 구함
기존 디코더
해당 모델의 디코더
- 컨텍스트 벡터 c는 인코더가 입력 문장을 매핑하는 일련의 annotation h에 따라 달라짐
- annotation h = 입력 문장의 각 단어(또는 시퀀스의 위치)에 대한 정보를 요약하고 표현한 벡터
- hj = 양방향 RNN을 통해 각 단어의 문맥 정보(앞뒤 단어의 정보)를 포함
- 입력 시퀀스 i번째 단어를 둘러싼 부분에 중점
- 컨텍스트 벡터 ci 는 어노테이션 hj와, 출력단어 yi간의 관련성을 나타내는 가중치 aij 의 가중합(soft alignment)으로 계산
- annotation h = 입력 문장의 각 단어(또는 시퀀스의 위치)에 대한 정보를 요약하고 표현한 벡터
- 가중치 ai의 각 어노테이션 hj는 aij로 계산
- eij = 정렬 점수: 위치 j 주변의 입력과 위치 i의 출력이 얼마나 잘 일치하는지 점수를 매기는 정렬 모델
→ 이 논문에서는 소프트맥스(softmax) 함수를 사용하여 정렬 가중치를 확률처럼 표현



- 정렬 모델 a
- 입력단어 xj와 출력단어 yi의 연관성을 계산하는 모델
- 순방향 신경망(feedforward neural network)으로 매개변수화
- 입력값(si-1, hj)에서 얼라인먼트 점수 eij 계산
- 번역 모델 전체(인코더, 디코더, 얼라인먼트 모델)가 하나의 손실 함수(loss function)를 공유하며 동시에 학습
- 차별점
- 기존과 달리 정렬이 잠재 변수(latent variable)로 간주되지 않음
- 대신 소프트 얼라인먼트(soft alignment)를 직접적으로 계산
- 이를 통해 비용 함수(cost function)의 그래디언트를 역전파
- 이 그래디언트는 얼라인먼트 모델뿐만 아니라 전체 번역 모델을 공동으로 학습하는 데 사용됨
- [상세] 어노테이션의 가중합(weighted sum) 계산
- =가능한 정렬에 대한 기대값(expected annotation) 계산
- aij = 타겟 단어 yi가 소스 단어 xi와 정렬되거나 번역될 확률 = 소프트 얼라인먼트 확률 → 특정 출력 단어가 특정 입력 단어와 얼마나 관련이 있는지를 측정
- ci = i번째 컨텍스트 벡터 = 출력단어 yi를 생성할 때 필요한 정보 ci = 확률 aij를 기반으로 한 모든 어노테이션에 대한 기대값 = 소스 문장의 각 단어 어노테이션 hj * 단어 관련 확률 aij 가중합
- 확률 aij , 관련 에너지 eij는 이전 은닉 상태 si-1를 기반으로 다음 상태 si를 결정하고, yi 생성 시 어노테이션 hj의 중요도 반영
→ 디코더에서 어텐션 메커니즘(attention mechanism) 구현
- 디코더는 소스 문장에서 주목할 부분을 결정
- 디코더에 어텐션 메커니즘을 부여함으로써, 소스 문장의 모든 정보를 고정된 길이의 벡터로 압축해야 하는 인코더의 부담을 덜 수 있음
- 정보가 어노테이션 hj 시퀀스 전체에 분산되며, 디코더가 필요에 따라 이를 선택적으로 검색(retrieve)할 수 있음
3.2 인코더
- 기존 방식: 일반적인 RNN은 입력 시퀀스 x를 첫 번째 기호 x1 부터 마지막 기호 xT까지 순서대로 읽으며, 각 시간 단계에서 이전의 정보를 활용해 새로운 상태 생성
- 제안된 방식: 각 단어의 주석이 앞 단어 뿐만 아니라 다음 단어도 요약하는 양방향 RNN(Bidirectional RNN) 사용 - 하여 단어별로 주변 정보를 포함한 어노테이션 벡터 생성
양방향 RNN(BiRNN) (Graves et al., 2013)
- 개념: 입력 데이터를 양방향으로 처리하는 신경망으로, 각 단어가 문맥적으로 앞뒤 단어의 정보를 모두 고려할 수 있도록 함
- 메커니즘
- 순방향 RNN: 입력을 x1→xT 순서 로 처리
- 역방향 RNN: 입력을 xT→x1 순서로 처리
- 각 단어의 어노테이션 hj는 순방향 은닉 상태와 역방향 은닉 상태를 연결(concatenate)하여 생성
- 특징
- RNN이 최근 입력값을 더 잘 표현하는 경향이 있기 때문에, 어노테이션 hj는 xj 주변 단어에 초점
- 이 어노테이션 시퀀스는 이후 디코더와 얼라인먼트 모델에 의해 컨텍스트 벡터를 계산하는 데 사용
4. 실험 설계
4.1 데이터셋
- WMT ’14의 영어-프랑스어 병렬 코퍼스 사용
4.2 모델
- 모델: 제안된 RNNsearch 모델과 기존 RNN Encoder-Decoder 모델(Cho et al., 2014a) 비교
- 방법론은 연구를 위해 보기!
- 모델 구조
- RNN Encoder-Decoder 모델
- 1000개의 숨겨진 유닛(hidden units)을 가진 순환 신경망(RNN)으로 구성
- 인코더는 입력 문장을 고정된 벡터로 압축하고, 디코더는 이 벡터를 기반으로 출력 문장을 생성
- RNNsearch 모델
- 양방향 순환 신경망 (Bidirectional RNN)으로 구성
- 디코더는 기존 RNNencdec와 마찬가지로 1000개의 숨겨진 유닛을 사용
- 디코더의 출력 단어를 생성할 때: 각 입력 단어의 가중치(얼라인먼트 점수)를 계산해, 동적으로 컨텍스트 벡터를 형성, 소프트 얼라인먼트를 통해 번역의 유연성과 품질 향상
- 공통점
- 디코더는 다층 네트워크를 사용하여 출력 단어의 조건부 확률을 계산
- 조건부 확률 계산 시, 단일 최대치(softmax) 활성화 함수를 사용
- RNN Encoder-Decoder 모델
- 학습 알고리즘
- Adadelta
- Adadelta (Zeiler, 2012) 알고리즘을 사용해 학습 속도 조절
- Adadelta는 학습률(learning rate)을 동적으로 변경해, 기울기 폭발(gradient explosion)과 소실(gradient vanishing)을 완화
- 확률적 경사 하강법 (SGD)
- 미니배치 확률적 경사 하강법(Stochastic Gradient Descent)을 사용
- 각 배치는 80개의 문장으로 구성
- 각 모델은 약 5일 동안 훈련
- Adadelta
- 번역 후보 선택: 빔 서치(beam search)
- 빔 서치는 출력 문장을 생성할 때, 확률이 높은 k개의 후보를 유지하며 가장 적합한 번역을 찾는 방법
- 최종적으로 조건부 확률을 최대화하는 번역을 선택
- 모델 구조
5. 결과
- 평가: BLEU 점수를 통해 번역 성능 평가
- cf) BLEU(Bilingual Evaluation Understudy) 점수
- 개념: 기계 번역(Machine Translation)의 품질을 자동으로 평가하는 가장 널리 쓰이는 지표. 번역된 출력 문장(candidate translation)이 참조 문장(reference translation)과 얼마나 유사한지를 정량적으로 측정
- 방법
- n-gram Precision (정확도): 번역된 문장에서 참조 문장과 일치하는 n-gram의 비율을 계산
- Brevity Penalty (길이 페널티)
- 번역된 문장이 지나치게 짧아지는 것을 방지하기 위해 추가된 요소
- 번역 문장의 길이가 참조 문장보다 짧을 경우 점수를 낮춤
- 공식: n-gram 정확도의 기하 평균(geometric mean)에 길이 페널티를 곱하여 계산
- cf) BLEU(Bilingual Evaluation Understudy) 점수
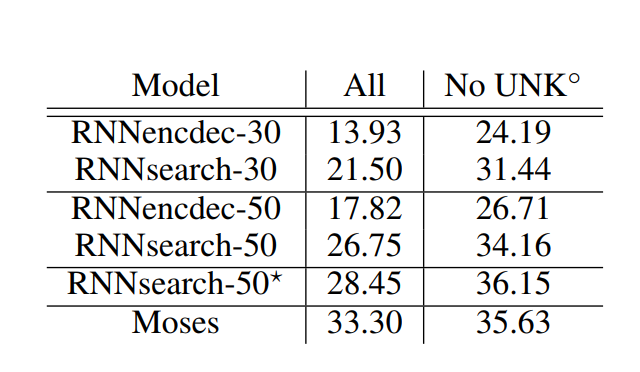
- 정량적 결과:
- 제안된 RNNsearch가 모든 문장 길이(30단어, 50단어)에서 기존 RNNencdec보다 성능이 뛰어남
- 알려진 단어로 구성된 문장만 고려했을 때(No UNK) RNNsearch의 성능이 기존 구문 기반 번역 시스템(Moses)의 성능만큼 높음
- 이는 RNNsearch와 RNNencdec의 학습에 사용한 병렬 말뭉치 외에 별도의 단일 언어 말뭉치(418만 단어)를 사용한다는 점을 고려할 때 의미있는 성과
- 정성적 분석:
- 정렬 학습: 소프트 얼라인먼트를 통해 단어 간 직관적인 정렬 시각화 가능 ↔ 하드 얼라인먼트
- 형용사와 명사는 일반적으로 프랑스어와 영어에서 서로 다른 순서를 갖고 있으나 정확히 인식
- 긴 문장: 긴 문장에서도 RNNsearch는 의미를 유지하며 올바른 번역 생성
- 정렬 학습: 소프트 얼라인먼트를 통해 단어 간 직관적인 정렬 시각화 가능 ↔ 하드 얼라인먼트
6. 관련 연구
- 기존 연구는 신경망을 통계적 번역 시스템의 일부로 사용했으나, 본 연구는 독립적인 NMT 시스템 개발에 중점
- 정렬 학습: Graves(2013) 손글씨 학습 연구
- 가우스 커널의 혼합을 사용하여 입력 문자 시퀀스와 출력 손글씨 사이의 정렬 가중치를 계산
- 차이점: 선행연구에서는 주석의 가중치 모드가 한 방향으로만 움직임 ↔ 해당 연구에서는 모든 단어의 주석 가중치를 계산해야 함
- 기계 번역과 신경망: Bengio et al.(2003) 신경 확률론적 언어 모델(NNLM) 제안
- 앞에 나오는 단어의 조건부 확률을 모델링
- 차이점: 선행연구에서는 기존 통계적 기계 번역 시스템에 하나의 기능을 제공
- 정렬 학습: Graves(2013) 손글씨 학습 연구
7. 결론
- 고정된 벡터를 사용하는 기존 인코더-디코더 방식의 한계를 극복하기 위해 소프트 얼라인먼트를 도입
- 긴 문장에서 뛰어난 성능을 보이며, 기존의 통계적 번역 시스템과 비슷한 수준의 성능 도달
- cf) 통계적 번역 시스템에 비해 갖는 의의
- 단일 모델 설계: SMT는 다중 구성 요소를 조합해야 했지만, 이 논문은 번역 과정(정렬, 번역, 문맥 처리)을 단일 신경망(NMT)으로 통합
- 자동 학습: 데이터에서 정렬, 번역 품질, 언어 규칙을 자동으로 학습. SMT처럼 사전에 번역 테이블이나 정렬 모델을 구축할 필요 없음
- 문맥 처리: SMT는 n-gram 기반으로 문맥을 제한적으로 처리했지만, 이 논문은 어텐션 메커니즘을 통해 더 긴 문맥을 고려
- cf) 통계적 번역 시스템에 비해 갖는 의의
- 향후 연구 방향은 희귀 단어나 미지의 단어 처리를 개선하는 데 초점
참고 문헌
Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural Machine Translation by Jointly Learning to Align and Translate. https://doi.org/10.48550/arxiv.1409.0473
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra
arxiv.org
Appendix
파란 글씨: 논문 외 추가적으로 찾아본 내용